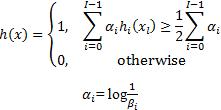In the Viola-Jones object detection algorithm, the training process uses AdaBoost to select a subset of features and construct the classifier. A large set of images, with size corresponding to the size of the detection window, is prepared. This set must contain positive examples for the desired filter (e.g. only front view of faces), and negative examples (nonfaces). Each image has index l, l = 1…L. For each image, a corresponding value yl, is established. yl=1 for faces and yl=0 for nonfaces.
Initialize weights ![]()
![]() , for yl=0,1 respectively where P– and P+ are the number of nonfaces and faces in the image set.
, for yl=0,1 respectively where P– and P+ are the number of nonfaces and faces in the image set.
The algorithm is executed for an arbitrary number of rounds, I.
For i = 1…I
- Normalize the weights as follows so that wi,l is a probability distribution:
![]()
![]()
- For each feature j, train a classifier hj which is restricted to using a single feature. The classifier’s error rate is evaluated with respect to wi,l:
![]()
![]()
- Choose the classifier, hi, with lowest error εi.
Update the weights:
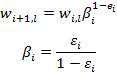 The final classifier is:
The final classifier is: