It is well known that as we increase the number of microphones in any array topology, we increase the signal to noise ratio (SNR) improvements that can be achieved. In some cases however, the system design limits the number of microphones that can be utilized. Conventional beamforming techniques that depend mainly on using a high number of microphones will give an improvement of  per power of 2 microphones that are deployed. Thus, using 2 microphones will give you about improvement over using a single microphone. This may not be good enough for speech recognition engines and a better approach has to be deployed. The use of least variance distortion-less response type approaches also require a lot of computation power which are not available for real time operating systems such as remote controls. A compromise has to be used.
per power of 2 microphones that are deployed. Thus, using 2 microphones will give you about improvement over using a single microphone. This may not be good enough for speech recognition engines and a better approach has to be deployed. The use of least variance distortion-less response type approaches also require a lot of computation power which are not available for real time operating systems such as remote controls. A compromise has to be used.
Consider a two microphones array as shown in Figure 1:
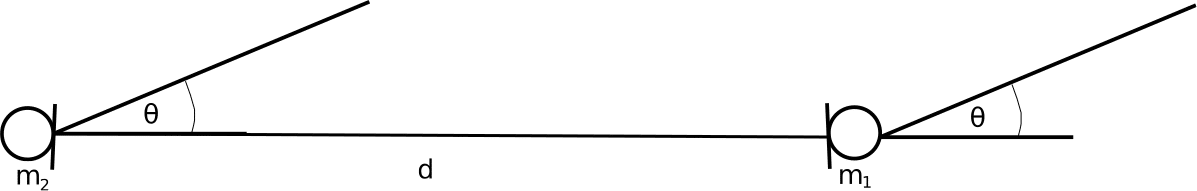
Figure 1: Two microphone array
If a virtual beam is formed in the middle of the two microphones, it can be assumed that there is a natural delay of  among the two microphone signals with one microphone taking the positive delay and the other taking the negative delay. A simple delay and sum approach will be to aggregate the two signals and weight each frequency bin
among the two microphone signals with one microphone taking the positive delay and the other taking the negative delay. A simple delay and sum approach will be to aggregate the two signals and weight each frequency bin  by the inverse of the effective filter below:
by the inverse of the effective filter below:
 = 2\cos{\left(w \frac{d F_s}{2c} \cos{\theta}\right)}")
where  is the sampling rate.
is the sampling rate.
This gives us a $3dB$ gain. A higher gain can be obtained if the direction of arrival , DoA, is known, by using a design parameter and taking a difference between the signals at microphones  and
and  to obtain a filter below:
to obtain a filter below:
 = 2 j \sin{\left(w \frac{d F_s}{2c} (\cos{\theta}+k)\right)}")
where  is the design parameter. In both cases, there is the need to find
is the design parameter. In both cases, there is the need to find  , which can be done through a number of algorithms such as GCC-PHAT. Sometimes, however, the desired look direction is known $a-priori$, making the implementation more computation friendly.
, which can be done through a number of algorithms such as GCC-PHAT. Sometimes, however, the desired look direction is known $a-priori$, making the implementation more computation friendly.
A sample result of this approach is shown in Figure 2 below where we get an SNR improvement of about  from 2 microphones, instead of
from 2 microphones, instead of  , with a known DoA of the signal of interest and not much increase in computations whilst avoiding non linear distortions.
, with a known DoA of the signal of interest and not much increase in computations whilst avoiding non linear distortions.
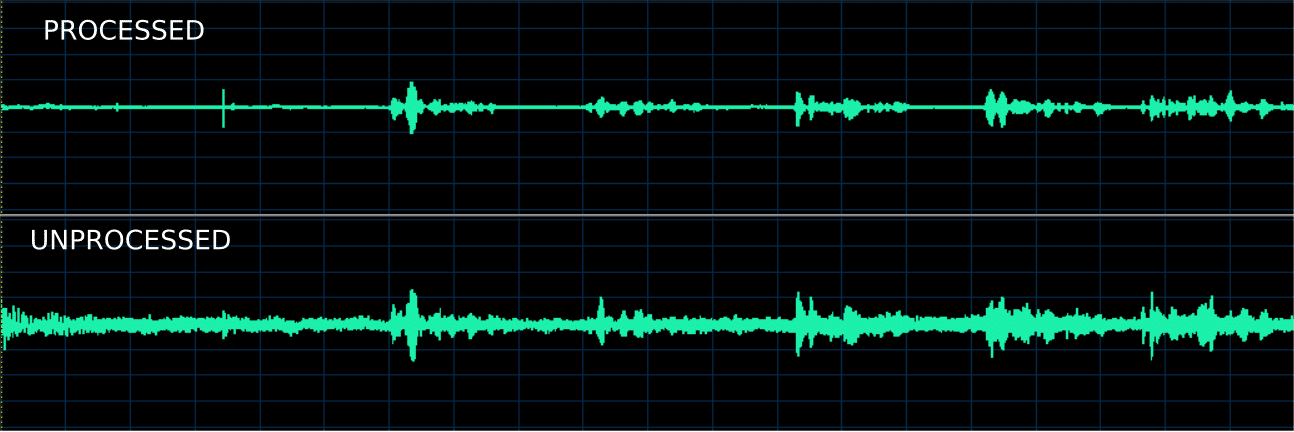
Figure 2: Two microphone array beamforming with known DoA
VOCAL Technologies offers custom designed solutions for beamforming with a robust voice activity detector, acoustic echo cancellation and noise suppression. Our custom implementations of such systems are meant to deliver optimum performance for your specific beamforming task. Contact us today to discuss your solution!
VOCAL Technologies offers custom designed solutions for beamforming with a robust voice activity detector, acoustic echo cancellation and noise suppression. Our custom implementations of such systems are meant to deliver optimum performance for your specific beamforming task. Contact us today to discuss your solution!