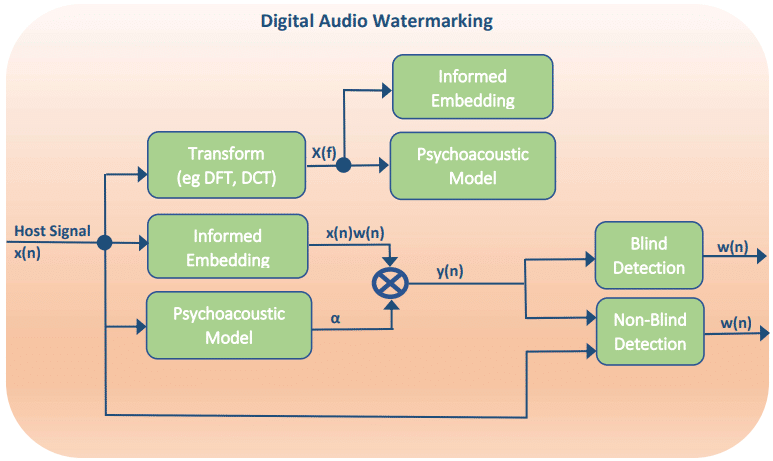
This article will provide a short summary of the different categories of digital audio watermarking embeddings and detection. The main differentiation of watermarking methods is between time domain and transform domain solutions. The general additive time domain formulization of watermarking is as follows
 = x(n) + \alpha w(n)")
where x(n) is the host signal, w(n) is the watermark,  is the watermark scaling factor, and y(n) is the watermark signal. While the general additive formulization of transform domain solutions is
is the watermark scaling factor, and y(n) is the watermark signal. While the general additive formulization of transform domain solutions is
 = X(f) + \alpha W(f)")
Where Y(f), X(f) and W(f) are the transform domain equivalents of the time domain signals.
These models are considered non-informed as the watermark embedded is not dependent on the host signal. A watermark signal is considered informed or non-informed when it uses the host signal to improve the embedding and extraction of the watermark. This modifies the model to include a multiplicative component. The equation for an informed solution is
 = x(n)+ \alpha w(x(n))")
Similarly, a non-blind detection scheme is dependent on having the original host signal for extraction of the watermark. Non-blind detection adds robustness to a system, but limits the applications for which it can be applied.
Another category of digital audio watermarking solutions, is whether a system uses the psychoacoustic model to modify the scaling factor over time andor frequency. Incorporating the psychoacoustic model of human hearing one can to improve on the imperceptibility of the presence of the watermark. The scaling factor then becomes dependent on the host signal and the human auditory system (HAS).
 = x(t)+ \alpha(x(t),HAS)w(x(t))")
By using HAS one can embed the watermark in the regions of the host signals that are deemed to be minimally perceptible.
VOCAL Technologies, Ltd. has 35+ years experience in signal processing and can utilize this expertise to design a system to meet specific customer requirements.