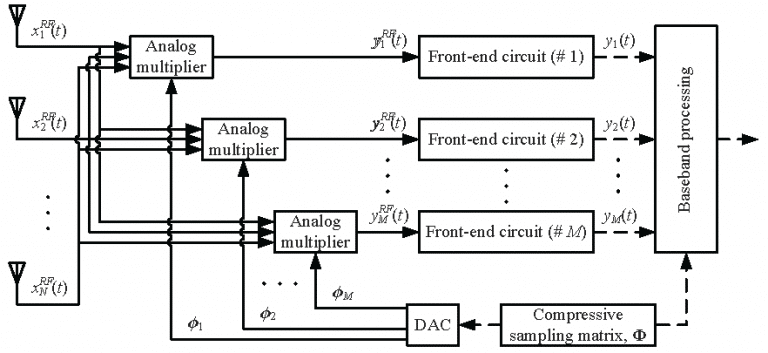
Considering the direction-of-arrival (DOA) estimation using compressive sampling array, as shown in Fig. 1, the compressive sensing matrix can be optimized by minimizing the minimum mean-square error (MMSE) of the parameter estimation as

or maximizing the mutual information between the compressive measurements and the parameter to be estimated as
. \nonumber")
Here,  and
and ") denote the statistical expectation and the mutual information, respectively. Both the objective functions are the implicit function of the compressive sensing matrix
denote the statistical expectation and the mutual information, respectively. Both the objective functions are the implicit function of the compressive sensing matrix  . Due to the relationship between mutual information and minimum mean-square error, the sensing matrix obtained from either optimization problems is the optimal one.
. Due to the relationship between mutual information and minimum mean-square error, the sensing matrix obtained from either optimization problems is the optimal one.
Simulation
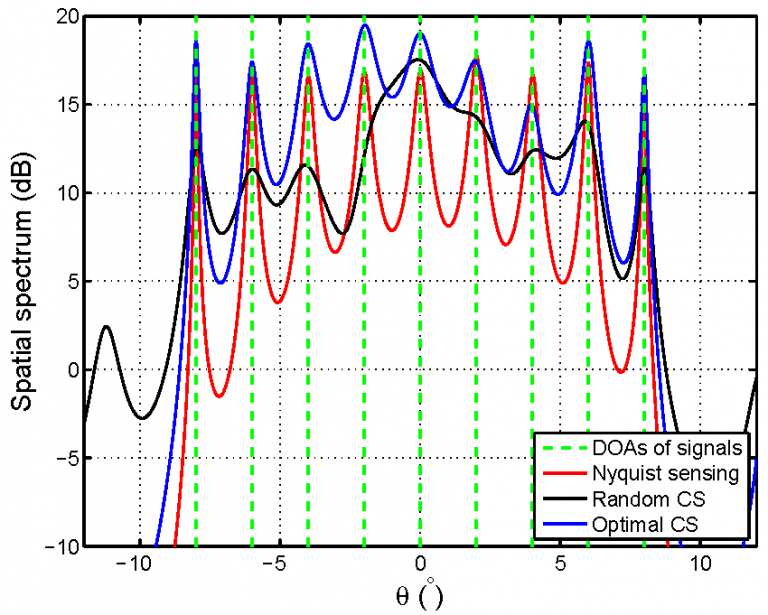
Assume a uniform linear array with 50 omnidirectional sensors equipped at the base station in a massive MIMO system. After 5 times compression, the dimension of the compressed measurement vector ") is reduced from 50 to 10. Fig. 2 compares the Capon spatial spectra of different compressive sampling schemes. Evidently, by exploiting the a priori knowledge of the users, the optimized compressive sampling can clearly identify the nine users as the Nyquist sampling, while the random compressive sampling does not provide sufficient resolution to identify all nine users.
is reduced from 50 to 10. Fig. 2 compares the Capon spatial spectra of different compressive sampling schemes. Evidently, by exploiting the a priori knowledge of the users, the optimized compressive sampling can clearly identify the nine users as the Nyquist sampling, while the random compressive sampling does not provide sufficient resolution to identify all nine users.