In a typical auditory environment, the onset of speech corresponds to a sudden increase in sound pressure level intensity whilst the drop off of speech corresponds to a sudden offset in the sound pressure level intensity. The interest in onset and offset of speech frames comes from the desire to extract features of only speech periods and not noise only frames especially when being used for auditory scene analysis. This detection becomes synonymous to edge detection as applied in image segmentation. A standard approach is to use a first order derivative of the sound pressure level with respect to time. The speech data available is sampled, hence, an approximation of the derivative using difference approach is used.
Suppose the received signal at the microphone is given as:
![y[n]= s[n] + \nu[n]](https://s0.wp.com/latex.php?latex=y%5Bn%5D%3D+s%5Bn%5D+%2B+%5Cnu%5Bn%5D&bg=ffffff&fg=000000&s=0 "y[n]= s[n] + \nu[n]")
where ![s[n]](https://s0.wp.com/latex.php?latex=s%5Bn%5D&bg=ffffff&fg=000000&s=0 "s[n]") is the desired speech signal and
is the desired speech signal and ![\nu[n]](https://s0.wp.com/latex.php?latex=%5Cnu%5Bn%5D&bg=ffffff&fg=000000&s=0 "\nu[n]") is i.i.d zero mean Gaussian noise with variance
is i.i.d zero mean Gaussian noise with variance  . The energy profile per frame is utilized, where the expectation of the energy profile is defined as:
. The energy profile per frame is utilized, where the expectation of the energy profile is defined as:
![e[n,N] \approx \sigma_{\nu^2} + \frac{1}{N}\sum\limits_{i=n}^{n + N} s^2[i]](https://s0.wp.com/latex.php?latex=e%5Bn%2CN%5D+%5Capprox+%5Csigma_%7B%5Cnu%5E2%7D+%2B+%5Cfrac%7B1%7D%7BN%7D%5Csum%5Climits_%7Bi%3Dn%7D%5E%7Bn+%2B+N%7D+s%5E2%5Bi%5D&bg=ffffff&fg=000000&s=0 "e[n,N] \approx \sigma_{\nu^2} + \frac{1}{N}\sum\limits_{i=n}^{n + N} s^2[i]")
Here, it is assumed that the speech and the noise signals are uncorrelated. The first order difference equation the becomes:
![D[n,N] \approx \frac{1}{N}\sum\limits_{i=n}^{n + N} \left(s^2[i] -s^2[i-1]\right)](https://s0.wp.com/latex.php?latex=D%5Bn%2CN%5D+%5Capprox+%5Cfrac%7B1%7D%7BN%7D%5Csum%5Climits_%7Bi%3Dn%7D%5E%7Bn+%2B+N%7D+%5Cleft%28s%5E2%5Bi%5D+-s%5E2%5Bi-1%5D%5Cright%29&bg=ffffff&fg=000000&s=0 "D[n,N] \approx \frac{1}{N}\sum\limits_{i=n}^{n + N} \left(s^2[i] -s^2[i-1]\right)")
In reality, the speech signal and the noise may not be totally uncorrelated. There will therefore be the need to smooth the signal to remove any residual noise in the estimate using a low pass filter. The use of a standard Gaussian filter defines as:
 = \frac{1}{\sqrt{2 \pi \sigma^2}} exp\left(-\frac{n^2}{2\sigma^2}\right)")
Instead of pre applying the Gaussian filter, a post filter can be used. In this instance, the derivative Gaussian filter has to be applied.The derivative filter is given as:
 = \frac{-n}{\sqrt{2 \pi \sigma^6}} exp\left(-\frac{n^2}{2\sigma^2}\right)")
where the derivative is with respect to time. The onset of speech corresponds to peaks whilst the offset corresponds to valleys. A threshold is used to used, centered about zero, to remove spurious peaks and valleys being returned.A sample performance of this algorithm is shown in Figure 1 below:
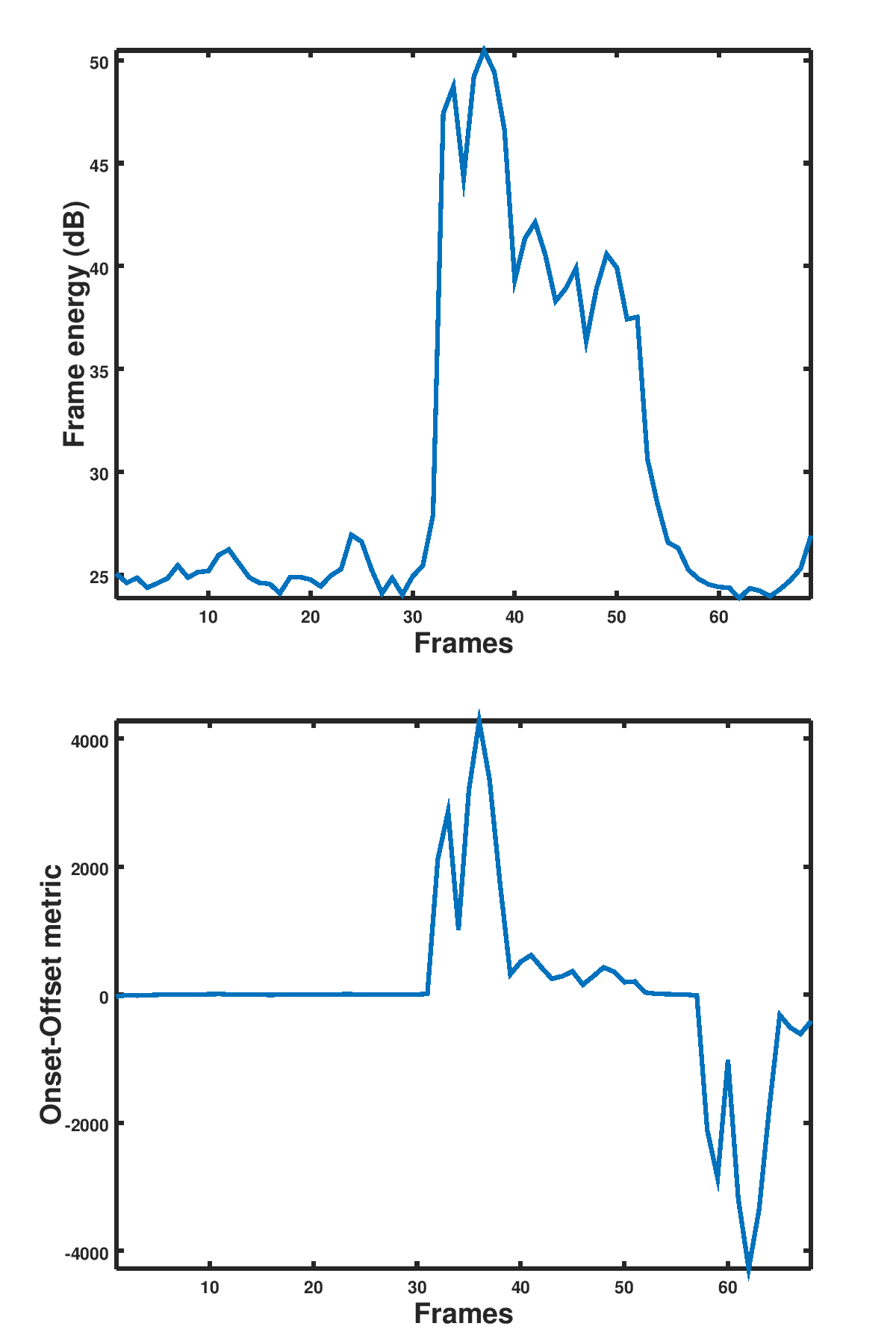
Figure 1: Speech onset and offset detection
VOCAL Technologies offers custom designed solutions for beamforming with a robust voice activity detector, acoustic echo cancellation and noise suppression. Our custom implementations of such systems are meant to deliver optimum performance for your specific beamforming task. Contact us today to discuss your solution!
More Information