For all speech enhancement algorithms, a voice activity detector (VAD) is utilized, not only to limit robust processing only during actual speech frames, but also to dynamically detect the noise floor. A VAD essentially is designed to distinguish noise from non noise frames. We can therefore use any number of the characteristics of noise which is not present in speech. One such characteristic is the number of zero crossings, which on average is less than the number observed in i.i.d. noise. Consider an zero crossing count based VAD, with the number of zero crossings computed computed by using a simple difference and comparator unit such that we count the number in a frame that satisfy ![y[n] - y[n-1] < y[n]](https://s0.wp.com/latex.php?latex=y%5Bn%5D+-+y%5Bn-1%5D+%3C+y%5Bn%5D&bg=ffffff&fg=000000&s=0 "y[n] - y[n-1] < y[n]") . Notice that this is true for both positive to negative transitions and negative to positive transitions. Suppose the received signal at the microphones are given as:
. Notice that this is true for both positive to negative transitions and negative to positive transitions. Suppose the received signal at the microphones are given as:
![y[n] = s[n] + \nu_i[n]](https://s0.wp.com/latex.php?latex=y%5Bn%5D+%3D+s%5Bn%5D+%2B+%5Cnu_i%5Bn%5D&bg=ffffff&fg=000000&s=0 "y[n] = s[n] + \nu_i[n]") where
where ![s[n]](https://s0.wp.com/latex.php?latex=s%5Bn%5D&bg=ffffff&fg=000000&s=0 "s[n]")
is the desired speech signal and ![\nu_i[n]](https://s0.wp.com/latex.php?latex=%5Cnu_i%5Bn%5D&bg=ffffff&fg=000000&s=0 "\nu_i[n]") is i.i.d zero mean Gaussian noise. Then, the threshold can be adaptively computed using the equation:
is i.i.d zero mean Gaussian noise. Then, the threshold can be adaptively computed using the equation:
![\alpha_T[n] = \beta_1 \underset{n}{argmax} \sum\limits_{m=0}^{M-1} ( y[n-m] - y[n-m-1] < y[n-m]) + (1-\beta_1) \underset{n}{argmin} \sum\limits_{m=0}^{M-1} ( y[n-m] - y[n-m-1] < y[n-m]))](https://s0.wp.com/latex.php?latex=%5Calpha_T%5Bn%5D+%3D+%5Cbeta_1+%5Cunderset%7Bn%7D%7Bargmax%7D+%5Csum%5Climits_%7Bm%3D0%7D%5E%7BM-1%7D+%28+y%5Bn-m%5D+-+y%5Bn-m-1%5D+%3C+y%5Bn-m%5D%29+%2B+%281-%5Cbeta_1%29+%5Cunderset%7Bn%7D%7Bargmin%7D+%5Csum%5Climits_%7Bm%3D0%7D%5E%7BM-1%7D+%28+y%5Bn-m%5D+-+y%5Bn-m-1%5D+%3C+y%5Bn-m%5D%29%29&bg=ffffff&fg=000000&s=0 "\alpha_T[n] = \beta_1 \underset{n}{argmax} \sum\limits_{m=0}^{M-1} ( y[n-m] - y[n-m-1] < y[n-m]) + (1-\beta_1) \underset{n}{argmin} \sum\limits_{m=0}^{M-1} ( y[n-m] - y[n-m-1] < y[n-m]))")
where  is the number of samples per frame and
is the number of samples per frame and  is a design parameter. A gradual decay and magnification is also used for the maximum and minimum levels to prevent being stuck at a spurious point. A sample performance of this algorithm is shown in Figure 1 below:
is a design parameter. A gradual decay and magnification is also used for the maximum and minimum levels to prevent being stuck at a spurious point. A sample performance of this algorithm is shown in Figure 1 below:
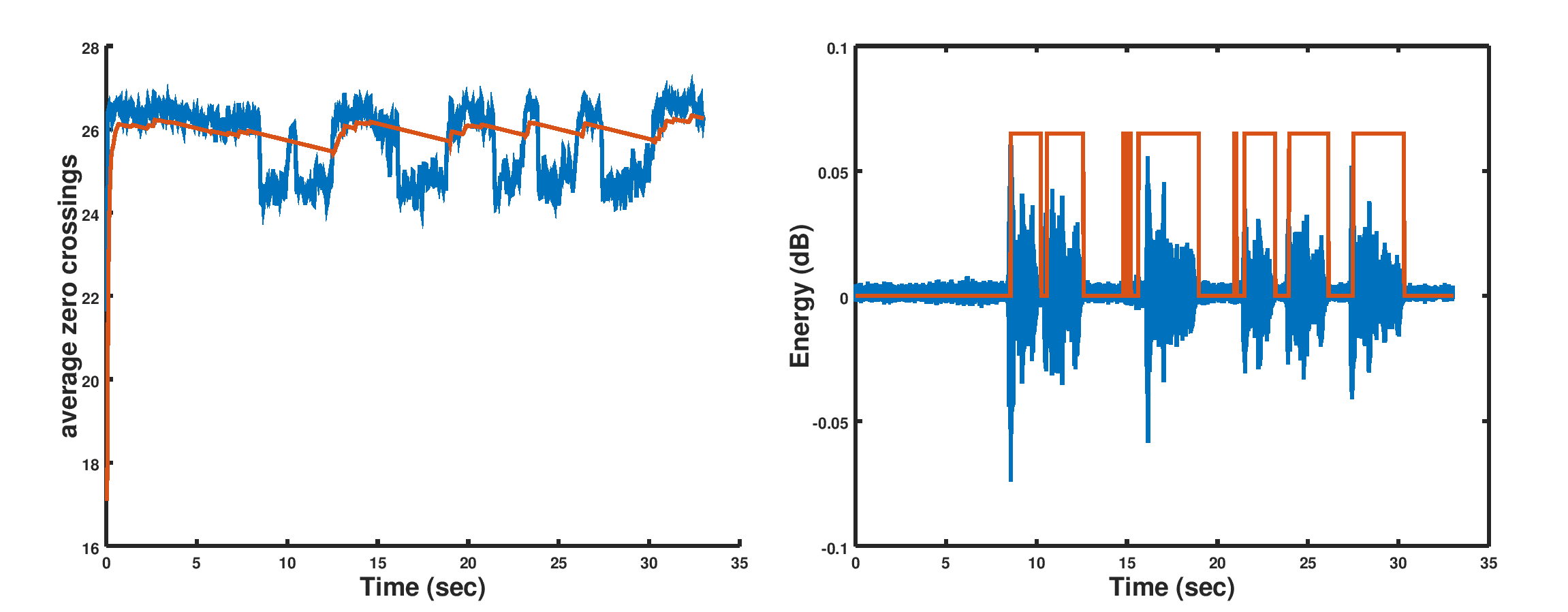
Figure 1: Adaptive VAD thresholding
VOCAL Technologies offers custom designed solutions for beamforming with a robust voice activity detector, acoustic echo cancellation and noise suppression. Our custom implementations of such systems are meant to deliver optimum performance for your specific beamforming task. Contact us today to discuss your solution!