Input feature selection plays an important role in the design of Speech Enhancement software utilizing neural networks (NN) for making the speech / noise classification. On one end, the input feature can simply the time domain PCM sample data, which places a heavy load on the learning machine. Convolution Neural Networks with Long Short-Term Memory learning machines are typically applied for end-to-end speech separation tasks, as they can model the temporal characteristics of speech.
To reduce the complexity of the learning machine, more discriminate features can be selected as inputs. Early research for single channel applications used the same monaural features as us humans do, such as pitch and amplitude modulation. These features were initially helpful, but more sophisticated speech characteristics were required for very low SNR applications. Additional features include autocorrelation, linear prediction, mel-domain and zero crossing, and all of their variations within. Deep Neural Networks are most often employed to improve the modeling abilities of the learning machine.
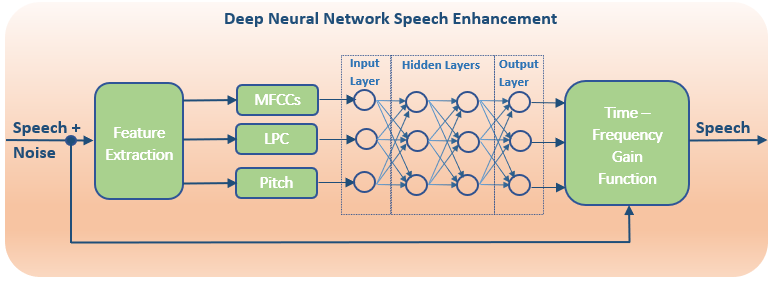
Evaluation of the input features has shown that the improvements to speech intelligibility is dependent on how the system is trained and the noise characteristics under test. The features that show the best overall performance are the mel-domain cepstral coefficients. Utilizing multiple features together, and multiple time-frequency scales improve performance, but increase the number of nodes/connections and computational complexity of the system.