Since 1979, the spectral subtraction algorithm and derivations thereof have dominated the speech enhancement landscape in academia and industry. The estimated statistics of the speech and noise signals from a noise corrupted speech signal are used to generate a time-frequency gain function, h(t,f). This gain function is used to subtract the noise component from the signal.
 = h(t,f) \cdot (s(t,f) + n(t,f))") (1)
(1)
It is typical for spectral subtraction algorithms to assume that noise is more stationary than the speech signal. Therefore, when faced with the cocktail party problem or other non-stationary noise sources (sirens, revving engines, etc), the spectral subtraction result will be unsatisfactory and unable to improve the speech intelligibility. Attempts to speed up the noise estimation process, will only lead to speech distortions and/or musical noise artifacts.
Speech enhancement needs to be transformed from a signal estimation problem to a signal classification problem. This is closer to how the human auditory system is able to solve this problem. Through auditory scene analysis we are able to isolate sound sources through a variety of time-frequency clues, such as harmonicity, onset and offset synchrony, amplitude and frequency modulations. To apply this as a speech enhancement algorithm, the time-frequency gain function from equation (1) is now dependent on the speech or noise classification from noisy speech signal features.
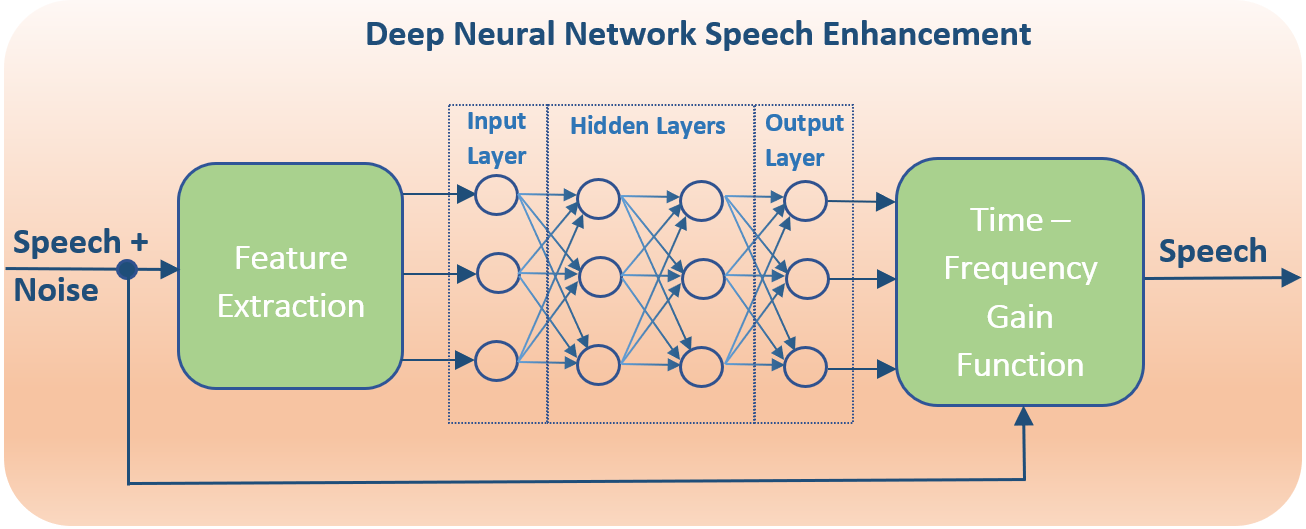
This classification problem is an ideal application for Deep Neural Networks (DNN). Deep learning has helped make rapid advancements in supervised learning tasks, such as automatic speech recognition and image identification. Many of the same concepts can be applied to speech enhancement. DNNs involves three main components, learning machines (the neural network), training process (the learning stage), acoustic feature extraction. A system is considered “deep” when it has multiple hidden layers. These additional layers help refined the classification result when properly trained. Subsequent articles will dive deeper in the main components of DNNs and how they are able to help solve the speech/noise classification problem.