Tonal input suppression is a well-known problem in the acoustic signal processing community. Music has strong tonal contents. People who wear hearing aids often have difficulty listening to music.
In a typical acoustic feedback application, when the input signal to a microphone is dominated by tonal contents, and a local speaker is used as the cancellation reference signal to avoid howling, the tonal contents of the desired signal can be heavily distorted. In extreme cases the tonal contents may be completely removed.
The root cause of the problem is the misuse of Wiener filter. Wiener filter is based on the assumption that the desired signal is uncorrelated with the reference signal. In the feedback case, the local desired tonal signal is highly correlated to the reference. The situation can be described by the following model.
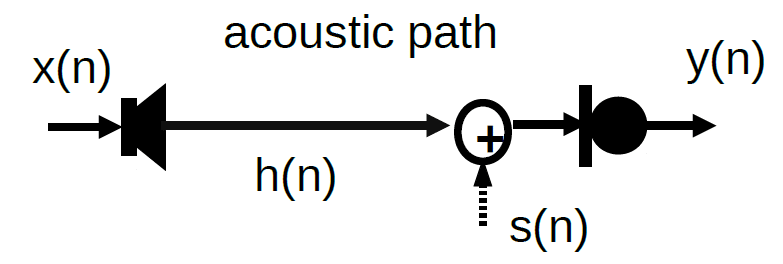
If s(n) is the desired signal, a local talker speech, for example, the microphone on the right captures the signal y(n) that is local desired talker speech plus the speaker output on the left,
y(n) = s(n) + x(n) * h(n),
where h(n) is the impulse response of the acoustic path from the speaker to microphone. We ignore the ambient noise for simplicity.
The goal of feedback cancellation is to obtain a robust approximation of s(n) from processing the microphone captured input y(n). However applying Wiener filtering directly will distort the tonal contents if x(n) is some delayed version of s(n).
VOCAL technologies introduces a robust approach to mitigate the tonal input suppression problem in addition to various commonly used practices. The following lists a few examples.
- Random jitter can be introduced in the signal path to break down correlation
- Perceptually insignificant masked noise can be used for long term adjustment
- Suppression or cancellation is decided by real time logic
- Frame-by-frame power growth rate is used to differentiate tonal input and feedback signals