Musical noise is heard when there are isolated peaks in the time-frequency spectrum of an audio signal. Musical noise has mostly been documented as an undesired artifact of noise reduction algorithms. See Musical Noise in Acoustic Noise Reduction. However, musical noise can be a result of a nonlinear processor in an acoustic echo cancellation (AEC) solution. This occurs in transform domain solutions where the residual echo gain function is applied independently to each frequency bin. This independence is great for the double-talk scenario, as you have the frequency selectivity to preserve the near-end signal. Given an echo canceller that transforms the time domain signal into 64 frequency bins, there are 64 decisions that need to be made. During the double-talk scenario, if one of those decisions is wrong for a single time instance, it can be masked by other neighboring frequencies and time periods which have near-end speech. However, during the echo-only scenario, one missed decision will leave an audible spectral peak.
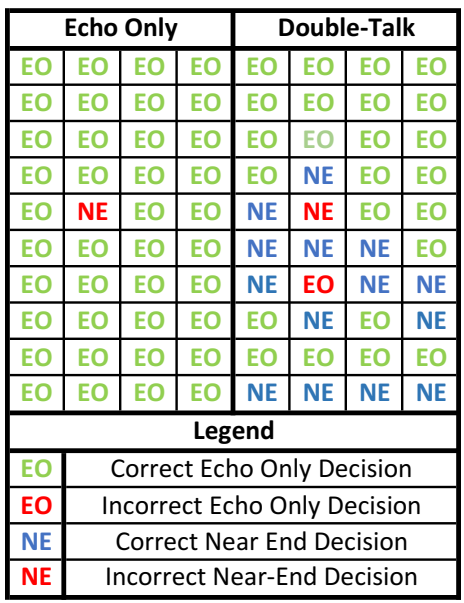
How do you mitigate this isolated decision error? You can use similar mitigation techniques used in noise reduction solutions. By applying a temporal and frequency-based smoothing of the gain function, the peak can be averaged out. Also, for voice applications, group decisions can be made. For example, if all of the neighboring frequency bins have concluded this is an echo-only scenario, then the current frequency bin has a high probability of being in an echo-only state too.