Deep Learning Based Voice Activity-Detection (DLVAD)
Traditional voice activity detector (VAD) may utilize multiple feature sets based on assumptions on the distribution of speech and noises. Model assumptions may not fully capture the data distribution due to the limited number of parameters. They may also not be flexible enough to fuse multiple features. Data-driven deep learning approaches have the potential to overcome both of the limitations.
Deep neural network (DNN)-based voice activity detector uses two classifier classes: speech class and silence class. The input vector of the DNN is constructed for every frame of the speech signal based on multi-resolution cochleagram (MRCG) features. MRCG is a concatenation of four cochleagram features with different window sizes and frame lengths. The cochleagram features are generated from gammatone filterbanks. The output vector is the posterior probabilities of these two classes. The output vector is computed for each input vector based on threshold respectively. The DNN can be trained for an input sequence and output sequence frame by frame.
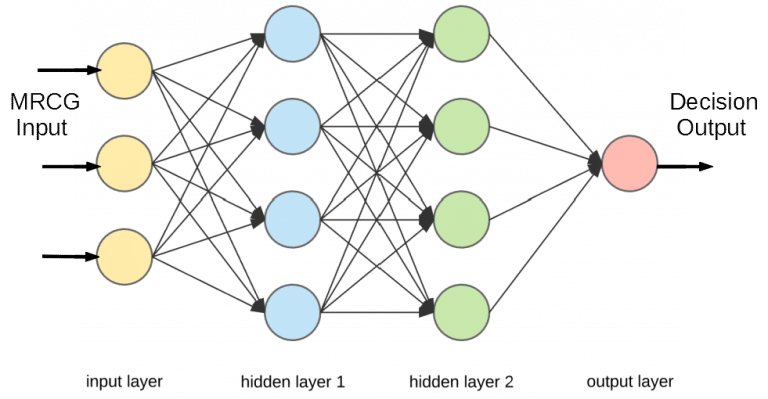
Figure 1 Deep Neural Network for Voice Activity Detection.
For training, the perfect binary mask that a VAD would create is used as the ground truth. It can be computed from the known speech-silence structure of the speech samples from a speech dataset. The testing speech can be created by applying 25ms frames with 10ms offset. MRCG feature vectors are computed frame by frame and used as the input to the input layer as shown in diagram in Figure 1. All the hidden layer weights are obtained from the training of the ground truth. The output layer produces the estimation decision of binary hypotheses.