Blind source separation is a technique used to separate multiple desired signals with no apriori knowledge of the signal source directions. We utilize this technique in separating two signals which hitherto would have been separated using endfire beamformer. This technique can be utilized in automobiles to pick the speech of a driver whilst removing that of the front seat passenger or vice versa.
Consider a far field source impinging 2 microphones as shown in Figure 1 with N =2:
Figure 1: N ULA microphones
Further, suppose there is an interfering speech signal anti phase to the desired signal. Our approach is to extract signal statistics from the captured signals and cluster the signals into three. The three speeche signals will correspond to the desired speech, the undesired speech and the background noise. no apriori information is used in the clustering, thus , this is an unsupervised clustering. After the three clusters are obtained, we pick the signal corresponding the cluster closest to our desired direction.
An example of the performance of this approach is shown in Figure 2 below:
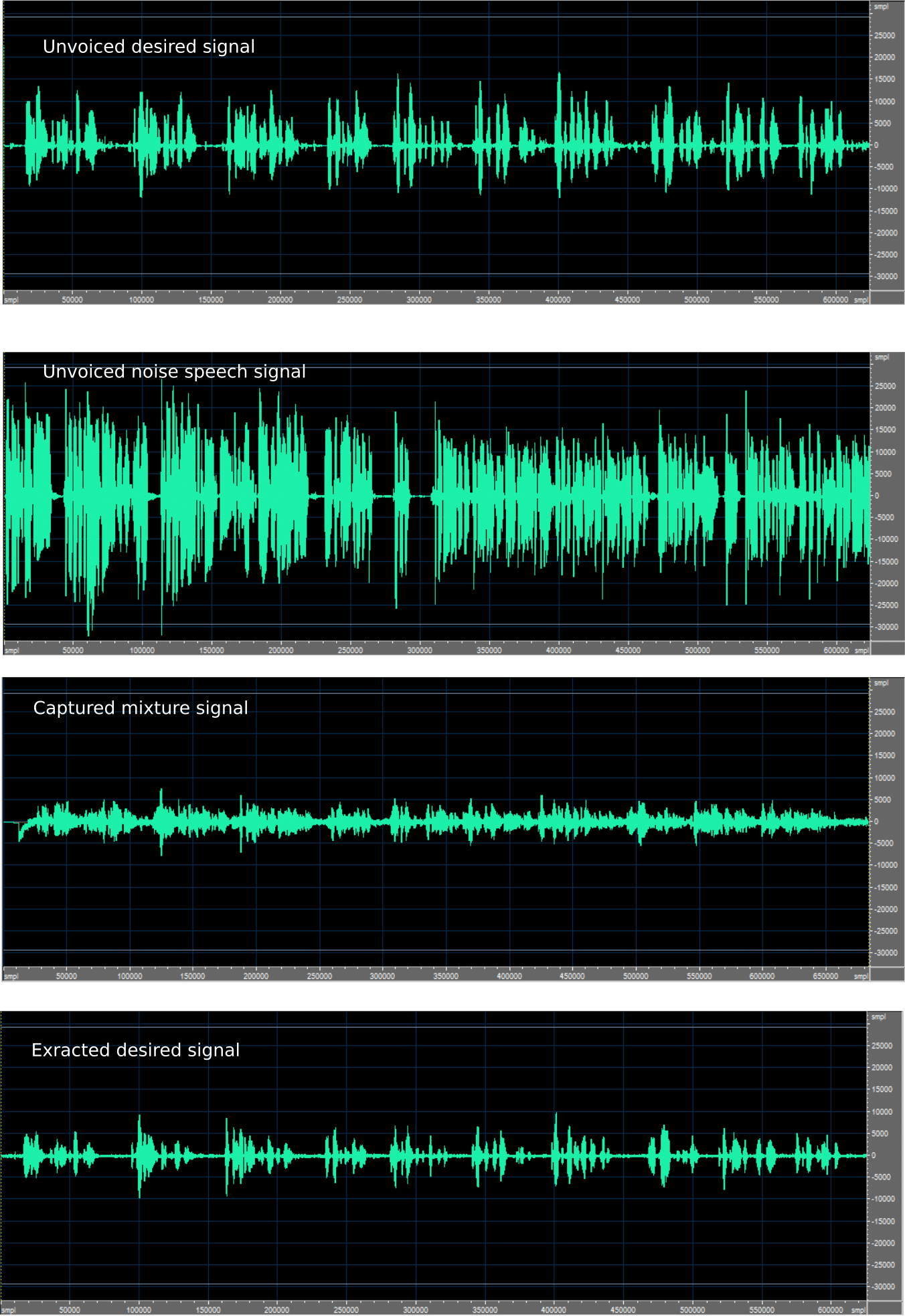
Figure 2: Desired signal on top row, extracted signal on bottom row. 
It can be seen that the desired signal is extracted. A single channel noise enhancement can be added to further improve the extracted signal quality.
As a custom design house, VOCAL Technologies offers custom designed solutions for blind signal separation with a robust voice activity detector, acoustic echo cancellation and noise suppression. Our custom implementations of such systems are meant to deliver optimum performance for your specific beamforming task. Contact us today to discuss your solution!