In many practical applications, a single microphone may not provide the necessary signal-to-noise(SNR) for human-to-human or human-to-machine communications. One example of such applications is in-car dialog systems for human-car interfacing. Multiple microphones or microphone arrays can be used to enhance desired speech and/or suppress interfering ambient noises.
With a single microphone, noise reduction algorithms rely solely on the temporal information of the sound wave. It is difficult to handle nonstationary interferences, such as fun or wind noises.
A generic model for a 2-mic/2-speaker microphone array can be written in matrix form as
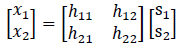
where 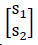 is the sound sources at the scene, and
is the sound sources at the scene, and 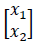 is the microphone captured signal, and
is the microphone captured signal, and 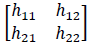 is the impulse responses from the sound sources to the microphones through the acoustic paths.
is the impulse responses from the sound sources to the microphones through the acoustic paths.
If we can invert the channel matrix, we can separate and recover each of the sound source as below.
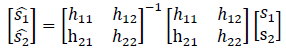
However this is not possible in most of the practical applications. The channel matrix is usually not available and, in the rare case when available, the matrix can be singular. When the numbers of microphones and speakers are not the same, the channel matrix will be rectangular.
Microphone array problems can be classified as multiple-input/multiple-output(MIMO) if the number of microphones and the number of speakers are all larger than one, and multiple-input/single-output(MISO) if the number of microphone is one.
If the knowledge of the target speaker is a priori, we can usually use this knowledge and design algorithms that are generally referred to as beamforming. If the ambient interference is stationary, fixed beamforming is sufficient; otherwise, we may use adaptive approaches such as linearly constraint minimum variance(LCMV) or minimum variance distortionless response (MVDR) type algorithms. If no knowledge of spatial information of the target source is available, the algorithms generally fall into blind source separation(BSS).
• Beamforming: when we know and use the knowledge of the location of the target sound source. In this category, we can further divide the algorithms into Fixed Beamforming, and Adaptive Beamforming.
• Blind Source Separation: when we have no information of the sound source and the sound source extraction is entirely from the multiple channel microphone captures.
It is obvious the beamforming class should perform better than the blind source separation class in general. VOCAL technologies provides microphone array algorithm solutions according the individual needs.