A first order endfire beamformer is used extensively when the desired noise source is anti phase to the desired signal using differential beamforming. It is however also desired that in the absence of such interfering signal, the algorithm should afford some performance improvements with regards to uncorrelated noise. The signal to noise ratio improvements using differential beamformer is different from the conventional delay and sum beamformer. We derive the expected SNR gains for uncorrelated noise on two microphones.
Consider a far field source impinging 2 microphones in an anechoic chamber as shown in Figure 1:
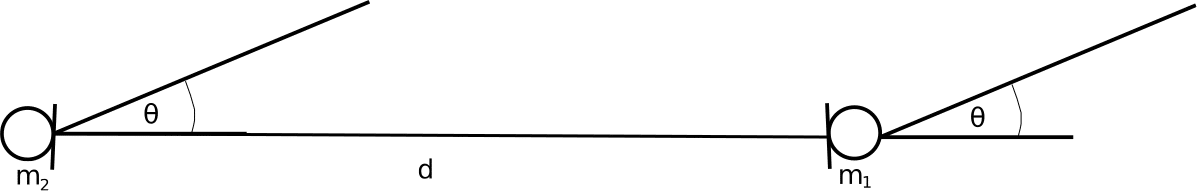
Figure 1: 2 microphone array
Suppose the signal at each microphone  is given as
is given as
 = s(w) e^{\left(-jw \frac{(i-1) d}{c} \sin{\theta} \right)} + n_i(w)")
where ") is the desired speech signal,
is the desired speech signal,  is the direction of arrival (DOA) of the speech signal with respect to the normal to the axis joining all the microphones, $n_i (w)$ is the uncorrelated noise. The noise signal is uncorrelated with the desired signal and across different microphones such that
is the direction of arrival (DOA) of the speech signal with respect to the normal to the axis joining all the microphones, $n_i (w)$ is the uncorrelated noise. The noise signal is uncorrelated with the desired signal and across different microphones such that
![\mathbb{E} [s(w) n_i^*(w)] = 0 \forall i \in \{1,2\}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D+%5Bs%28w%29+n_i%5E%2A%28w%29%5D+%3D+0+%5Cforall+i+%5Cin+%5C%7B1%2C2%5C%7D&bg=ffffff&fg=000000&s=0 "\mathbb{E} [s(w) n_i^*(w)] = 0 \forall i \in \{1,2\}")
and
$\mathbb{E} [n_i(w) n_j^*(w)] = 0, i \neq j, \{i,j\} \in \{1,2\}$
where ![\mathbb{E}[.]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B.%5D&bg=ffffff&fg=000000&s=0 "\mathbb{E}[.]") is the expectation operator. For endfire configuration,
is the expectation operator. For endfire configuration,  is the assumption. The input SNR per frequency bin
is the assumption. The input SNR per frequency bin  , denoted
, denoted ") is given as:
is given as:
![iSNR = \frac{\mathbb{E}\left[|s(w)|^2 \right]}{\mathbb{E}\left[\left |n_1(w)\right|^2 \right]} = \frac{|s(w)|^2}{\sigma_n^2}](https://s0.wp.com/latex.php?latex=iSNR+%3D+%5Cfrac%7B%5Cmathbb%7BE%7D%5Cleft%5B%7Cs%28w%29%7C%5E2+%5Cright%5D%7D%7B%5Cmathbb%7BE%7D%5Cleft%5B%5Cleft+%7Cn_1%28w%29%5Cright%7C%5E2+%5Cright%5D%7D+%3D+%5Cfrac%7B%7Cs%28w%29%7C%5E2%7D%7B%5Csigma_n%5E2%7D&bg=ffffff&fg=000000&s=0 "iSNR = \frac{\mathbb{E}\left[|s(w)|^2 \right]}{\mathbb{E}\left[\left |n_1(w)\right|^2 \right]} = \frac{|s(w)|^2}{\sigma_n^2}")
After the differential beamformer, the output becomes:
 = s(w) \left(e^{\left(-jw \frac{d}{c}\right)} -e^{\left(-jw \frac{d}{c} \sin{\theta} \right)}\right) + \left(n_1(w) e^{\left(-jw \frac{d}{c} \right)} -n_2(w)\right)")
The output SNR per frequency bin , denoted ") is given as
is given as
![oSNR = \frac{\mathbb{E}\left[|s(w)|^2 |1 - \cos{(w \frac{d}{c} (1-\sin{\theta}))}|\right]}{\mathbb{E}\left[|n_1(w)|^2 + |n_2(w)|^2 - 2 * \mathbb{R}e\{n_1(w) n_2^*(w) e^{(-jw\frac{d}{c})} \}\right]}](https://s0.wp.com/latex.php?latex=oSNR+%3D+%5Cfrac%7B%5Cmathbb%7BE%7D%5Cleft%5B%7Cs%28w%29%7C%5E2+%7C1+-+%5Ccos%7B%28w+%5Cfrac%7Bd%7D%7Bc%7D+%281-%5Csin%7B%5Ctheta%7D%29%29%7D%7C%5Cright%5D%7D%7B%5Cmathbb%7BE%7D%5Cleft%5B%7Cn_1%28w%29%7C%5E2+%2B+%7Cn_2%28w%29%7C%5E2+-+2+%2A+%5Cmathbb%7BR%7De%5C%7Bn_1%28w%29+n_2%5E%2A%28w%29+e%5E%7B%28-jw%5Cfrac%7Bd%7D%7Bc%7D%29%7D+%5C%7D%5Cright%5D%7D&bg=ffffff&fg=000000&s=0 "oSNR = \frac{\mathbb{E}\left[|s(w)|^2 |1 - \cos{(w \frac{d}{c} (1-\sin{\theta}))}|\right]}{\mathbb{E}\left[|n_1(w)|^2 + |n_2(w)|^2 - 2 * \mathbb{R}e\{n_1(w) n_2^*(w) e^{(-jw\frac{d}{c})} \}\right]}")
![oSNR = \frac{\left[|s(w)|^2 |1 - \cos{(w \frac{d}{c} (1-\sin{\theta}))}|\right]}{2 \sigma_n^2}](https://s0.wp.com/latex.php?latex=oSNR+%3D+%5Cfrac%7B%5Cleft%5B%7Cs%28w%29%7C%5E2+%7C1+-+%5Ccos%7B%28w+%5Cfrac%7Bd%7D%7Bc%7D+%281-%5Csin%7B%5Ctheta%7D%29%29%7D%7C%5Cright%5D%7D%7B2+%5Csigma_n%5E2%7D&bg=ffffff&fg=000000&s=0 "oSNR = \frac{\left[|s(w)|^2 |1 - \cos{(w \frac{d}{c} (1-\sin{\theta}))}|\right]}{2 \sigma_n^2}")
The SNR improvement, SNRI then becomes
)}|}{2}")
The SNRI improvement is a function of only the separation distance  . A sample expected SNRI at a frequency of
. A sample expected SNRI at a frequency of  is shown in Figure 2 below for different separation distances d. The desired direction is
is shown in Figure 2 below for different separation distances d. The desired direction is  . It can be seen that the SNRI degrades smoothly as increases but there are periodic distortions if a large value of $d$ is utilized. Thus, the magnitude of plays a huge role in the expected SNRI.
. It can be seen that the SNRI degrades smoothly as increases but there are periodic distortions if a large value of $d$ is utilized. Thus, the magnitude of plays a huge role in the expected SNRI.

Figure 2: SNRI (dB) for different }
VOCAL Technologies offers custom designed solutions for beamforming with a robust voice activity detector, acoustic echo cancellation and noise suppression. Our custom implementations of such systems are meant to deliver optimum performance for your specific beamforming task. Contact us today to discuss your solution!