There are always two competing objectives for online beamforming of speech frames. The first is accuracy, or improvement in signal to noise ratio (SNR). The second is the number of computations required to deliver the output. Least variance distortionless response is well known for delivering extremely good results in terms of SNR improvements. It however has a drawback in the computational burden per frame to deliver this distortionless response of the desired signal whiles attenuating the noise considerably.
In this regard, we present a distortionless response on the aggregate sum of the received signals and demonstrate that this achieves both considerable improvement in SNR and reduction in computational burden.
Consider an acoustic signal impinging a three microphones arranged as in Figure 1.
Figure 1: 3 microphone configuration
Suppose the signal at a microphone  ,
,  , can be denoted as
, can be denoted as
 = s(t-\tau_i) + \nu_i(t)")
where ") is the source signal,
is the source signal,  is the delay from the source at microphone and
is the delay from the source at microphone and ") is noise. Both and
is noise. Both and ") are zero mean ergodic processes. It can be shown that the received signal at all three micrphones can be summed up to attain
are zero mean ergodic processes. It can be shown that the received signal at all three micrphones can be summed up to attain
 = S(w) \frac{1}{3} H(w) + \frac{1}{3} \sum\limits_{i=1}^3 N_i(w)")
where
 = 2 \cos\left(w \frac{d}{2c} \sin{\theta} \right) + e^{-j w \frac{d}{c} \cos{\theta}}")
Using ") , a scalar distortionless response can be attained using
, a scalar distortionless response can be attained using ^H") , where the superscript
, where the superscript  denotes the hermitian operator, without the need of any matrix inversions, such that the frequency response shown in Figure 2 can be attained. Further SNR improvements are possible using the spatial filters corresponding to specific look directions.
denotes the hermitian operator, without the need of any matrix inversions, such that the frequency response shown in Figure 2 can be attained. Further SNR improvements are possible using the spatial filters corresponding to specific look directions.
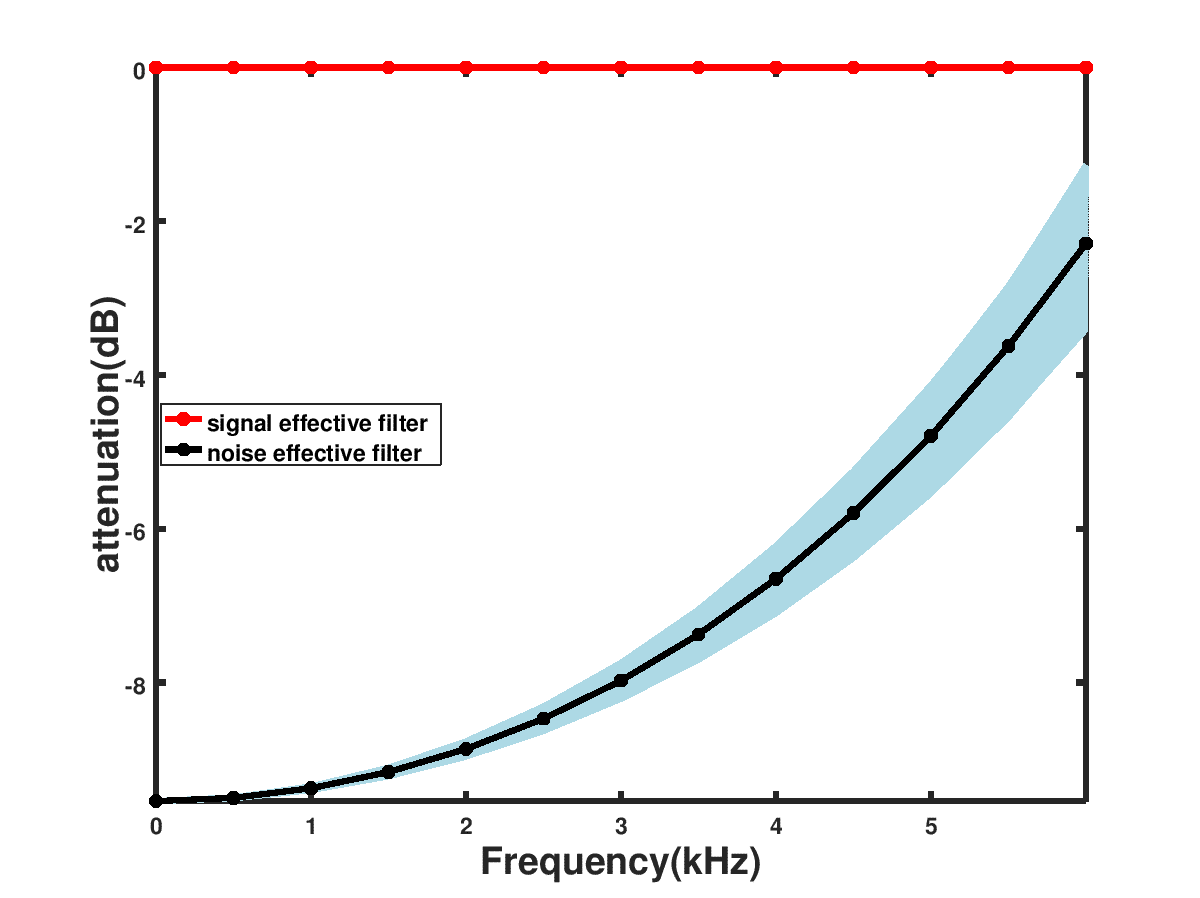
Figure 2: 3 microphone configuration results
VOCAL Technologies offers custom designed direction of arrival estimation solutions for beamforming with a robust voice activity detector, acoustic echo cancellation and noise suppression. Our custom implementations of such systems are meant to deliver optimum performance for your specific beamforming task. Contact us today to discuss your solution!